











Your QA scores how agents sound, not whether they were right.
The manager of instructional design at a global payments platform told us something that stuck with us:
"I just want a single rubric item called accuracy. I want to know: is this person speaking about our product correctly?"
That's it. Just: was what the agent said true? It's not an isolated request. We’ve heard some version of that question in dozens of separate customer conversations, across healthcare, financial services, technical support, and contact centers of every size. While the specifics varied, the underlying ask was always the same.
The question sounds simple. But answering it well gets at something real about where call center QA stands today, and where it falls short.
The finding appears in QA reports every week: "The agent gave incomplete information." It's a judgment, not a fact. And when you're sitting across from an agent trying to explain why their performance needs to change, the difference matters.
The agent can contest it. Another reviewer might score the same interaction differently. And if you're in a regulated industry like healthcare, financial services, or government services, it won't hold up in a compliance audit. "Our AI evaluated it that way" is not a defensible record.
This is the ceiling most QA programs have quietly accepted. The teams using them care about accuracy, but their QA tools were never built to evaluate it.
What call center quality assurance doesn't measure
Modern QA tools have gotten genuinely good at measuring conversation behavior. Tone, empathy, structure, pacing, adherence to call flow. These are real performance dimensions, and tools that measure them well are genuinely useful.
But they share a common limitation. They can tell you how a conversation went, but they can't tell you whether what the agent said was right.
This isn't a small gap. Think about the interactions that generate the most potential downstream damage: a patient who receives incorrect information about a medication, an agent who quotes a benefits figure that changed last quarter, a rep who describes a returns policy that no longer exists. These conversations often look fine on behavioral scoring. Appropriate tone, correct structure with no red flags, because the problem isn't how the agent sounded, it's what they said.
In industries where accuracy isn't optional, behavioral scoring alone doesn’t provide the full picture.
Why the accuracy gap exists
Here's what makes accuracy scoring genuinely hard: “right” means something different for every organization. To score whether what an agent said was right, the scoring engine needs to know what right looks like, and that context is distributed in policy manuals, compliance frameworks, clinical guidelines, or product documentation – documents that are specific, updated regularly, and genuinely hard to encode into a generic scoring rubric.
Behavioral scoring works because communication principles are largely consistent across contexts. Accuracy scoring requires knowing your context specifically.
A lot of tools today claim to use your knowledge base. They're doing very different things with it. Some surface relevant articles during a live call, helping agents find answers in real time. Others use uploaded documents to generate training content or simulation prompts. Both are useful. Neither evaluates whether what the agent actually said aligned with the standard those documents define. That's a different capability entirely, and it's the one most QA programs are still missing.The workaround has been manual encoding by QA admins: take the policy, break it into claims, enter those claims as scoring criteria. Most teams who've tried this know how it goes. It works until the policy changes. Then it breaks, and someone has to go fix it. In practice, many teams either maintain that burden at significant cost, or give up on accuracy scoring entirely.
That’s how you end up with QA programs that catch how agents sound, but miss what they say.
What changes when a finding has a citation
Every QA manager knows how the coaching conversation goes when the finding can't be substantiated. The agent pushes back:
"That's your interpretation."
"Another reviewer scored it differently."
"I don't see what I did wrong."
Often it's a reasonable response. And without something concrete to point to, the conversation stalls.
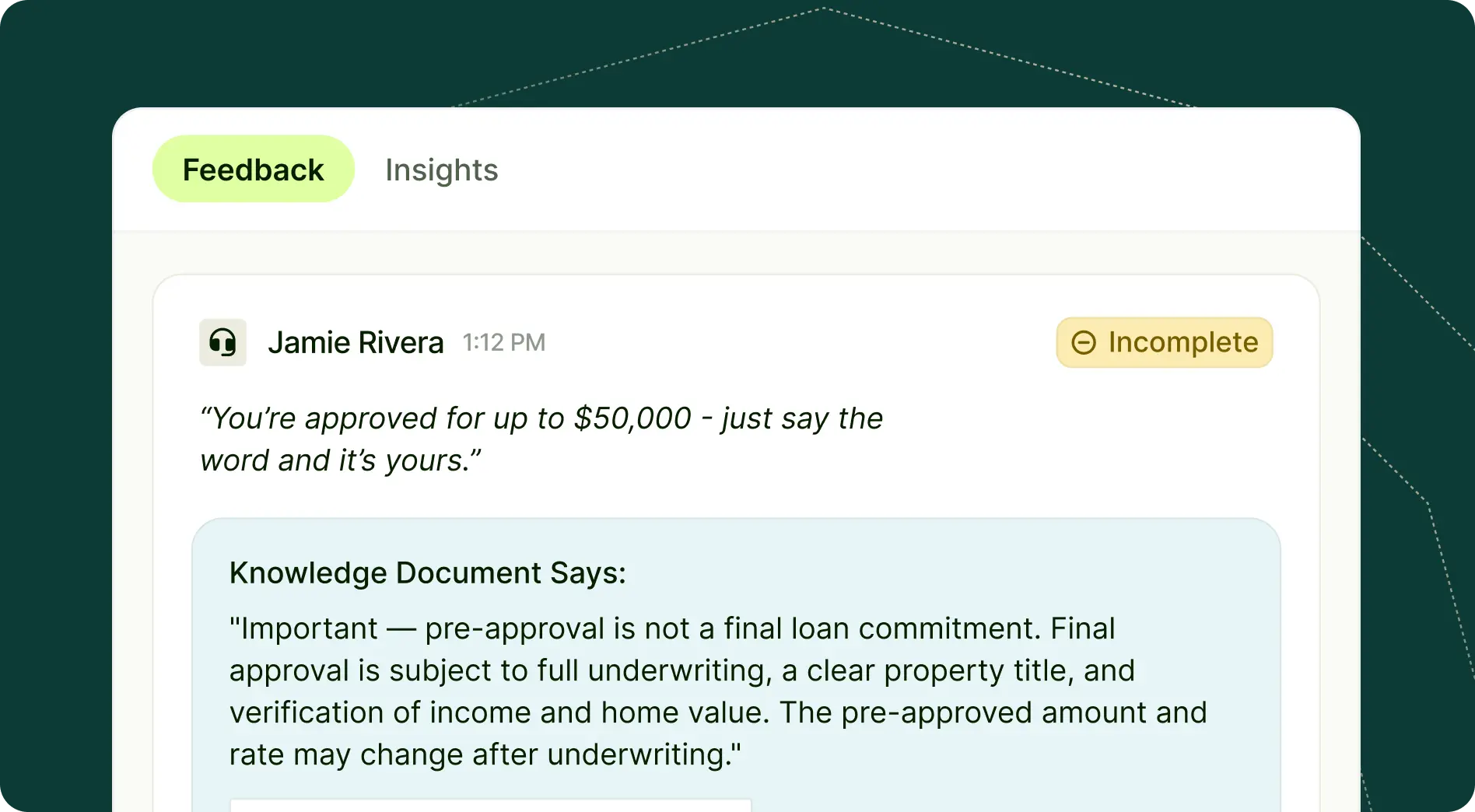
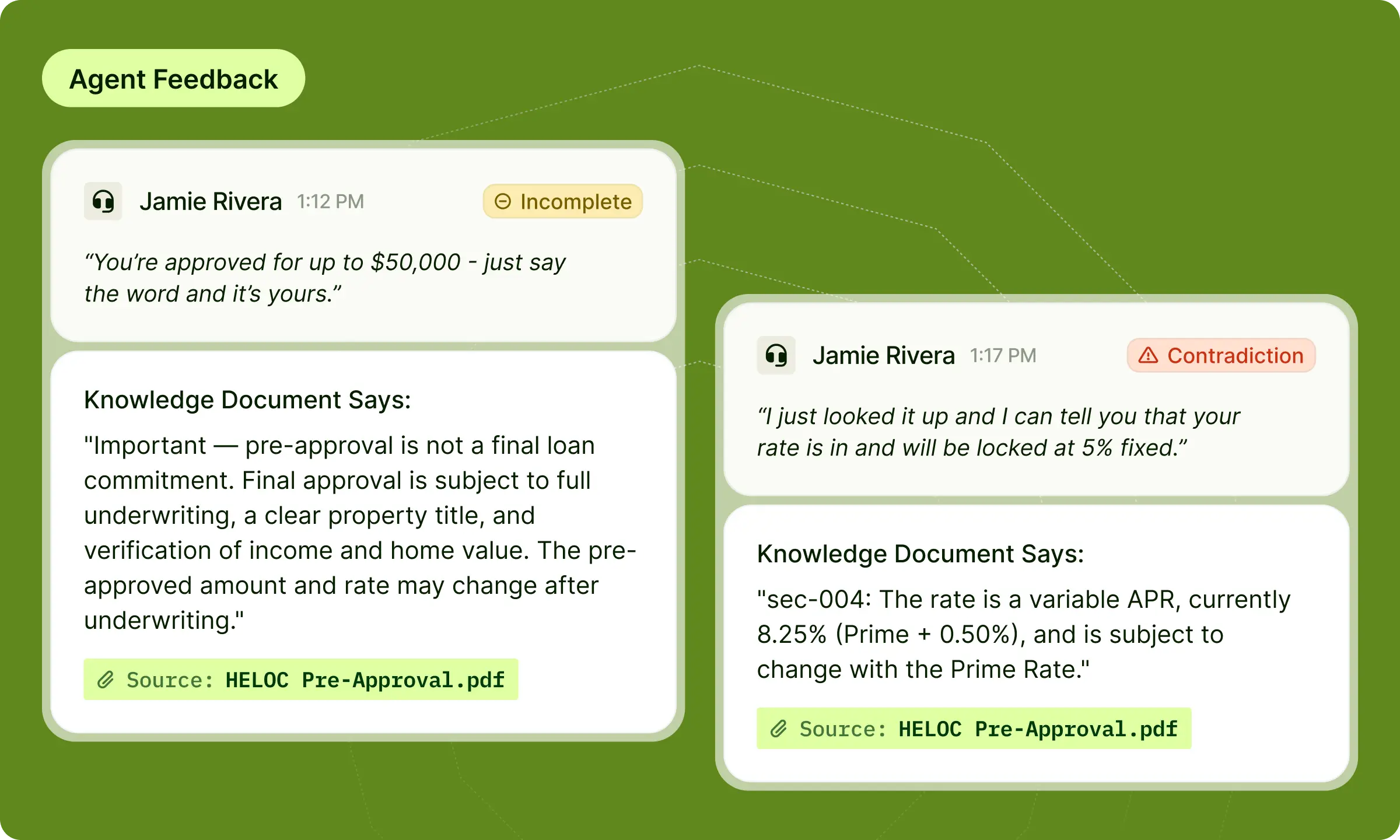
Citation-backed accuracy findings change that dynamic. When a scoring dimension is grounded in an organization's own documents, every accuracy finding points to the specific passage that was missed or contradicted. Instead of a flag, it's a reference: this is what your organization says is true, and here's where the agent's statement diverged from it. Every finding classifies the statement as fully supported, partially supported, contradicted, or unsupported, and shows exactly where in the knowledge base that determination comes from.
That includes what the agent got right. The output isn't just a list of errors. It's a complete accuracy picture, with citations confirming correct claims alongside the ones that missed or contradicted the document.Incomplete statements are distinct from contradictions, and they're often the harder problem to catch. An agent who tells a customer that early withdrawal on their account is permitted isn't wrong. But if they don't mention the 10% penalty and the tax implications, the customer hangs up with a picture of reality that will cost them real money. Citation-backed scoring surfaces that gap just as clearly as a direct contradiction.
This is what auditable AI looks like in practice. That has two practical effects. First, it makes the coaching conversation different. The agent isn't being asked to accept an AI's judgment about their performance. They're being shown a specific passage from a document their organization wrote and asked what happened. Second, for teams operating in regulated environments, it means QA records are audit-ready, because the evidence behind every score is visible and traceable.
There's also an anti-hallucination dimension worth naming directly. An AI-powered scoring system that can infer beyond its source material creates a new category of risk: findings that can't be traced back to anything the organization actually said was true. Citation-backed scoring eliminates that risk. If a topic isn't covered in the knowledge base, scoring abstains rather than infers. The constraint is the point: transparent, auditable AI by design, not by configuration.
Knowledge Validation: the accuracy layer
Knowledge Validation is ReflexAI's AI-powered accuracy scoring feature, built on the principle described above: every finding is grounded in the organization's own documents, every determination is traceable to a specific passage, no inference or hallucination beyond what the source material says.
ReflexAI has always evaluated how agents communicate: the tone, the empathy, the structure. Knowledge Validation adds the ability to assess whether what they said was right.
QA admins upload documents to the Resource Library, attach them to a scoring dimension, and every conversation scored against that dimension is evaluated against the organization's source of truth. Each statement is classified as fully supported, partially supported, contradicted, or unsupported, and every finding shows exactly where in the knowledge base that determination comes from.
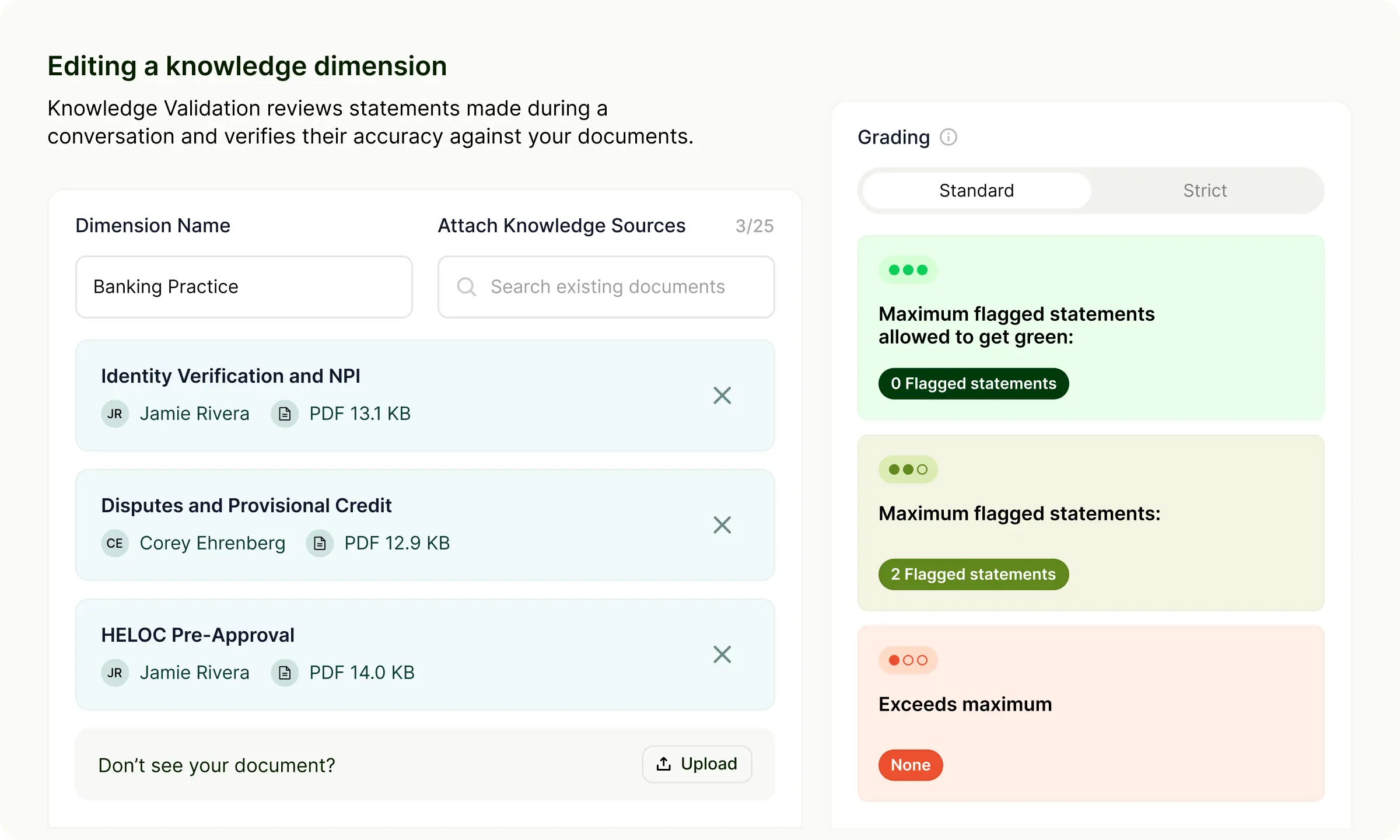
The same mechanism works across both ReflexAI products. In Assure, it validates whether what agents said in live conversations aligns with policy. In Prepare, it evaluates whether trainees are practicing against the actual standard they'll be held to in production. One standard, both directions.
That's the shift from behavioral accountability to accuracy accountability. For QA teams, that's a finding they can actually stand behind.
Want to see what accuracy scoring looks like against your own documents? Request a demo and we'll walk you through Knowledge Validation with your actual content.