













The Context
Contact center leaders don’t lack awareness. More often than not, they know which calls go wrong, which agents struggle, and which topics cause friction. The problem isn’t insight: it’s the gap between having that insight and being able to act on it quickly, precisely, and at scale.
In a survey of over 100 contact center leaders, a vast majority have deployed AI QA tools – yet fewer than 40% say they’re effectively using AI across their operations. Fewer than half say their training tools meet their needs, and roughly the same for QA. The report identified a classic “insight-to-action funnel leak”: around three-quarters regularly review calls, but only about half can take action on trends, and fewer still can measure whether those actions worked.
Time compounds the problem. Fewer than 30% have enough time for value-add work. Training managers are spending hours manually annotating transcripts. And the feedback loop between quality findings and training is, in most organizations, broken.
“Our training program does not tie in with actual deficiencies identified in the QA process.”
How ReflexAI Closes the QA-Training Loop
At ReflexAI, we believe that what happens in live interactions should directly inform how agents practice, and what happens in practice should measurably improve live performance. That’s not a tagline, it’s the architecture of our product. Each capability we’ve built feeds into the next, forming a continuous loop: see what’s happening, understand why, pinpoint the specific moments that matter, and turn all of it into targeted practice.
Here’s how each piece works, and how they connect.
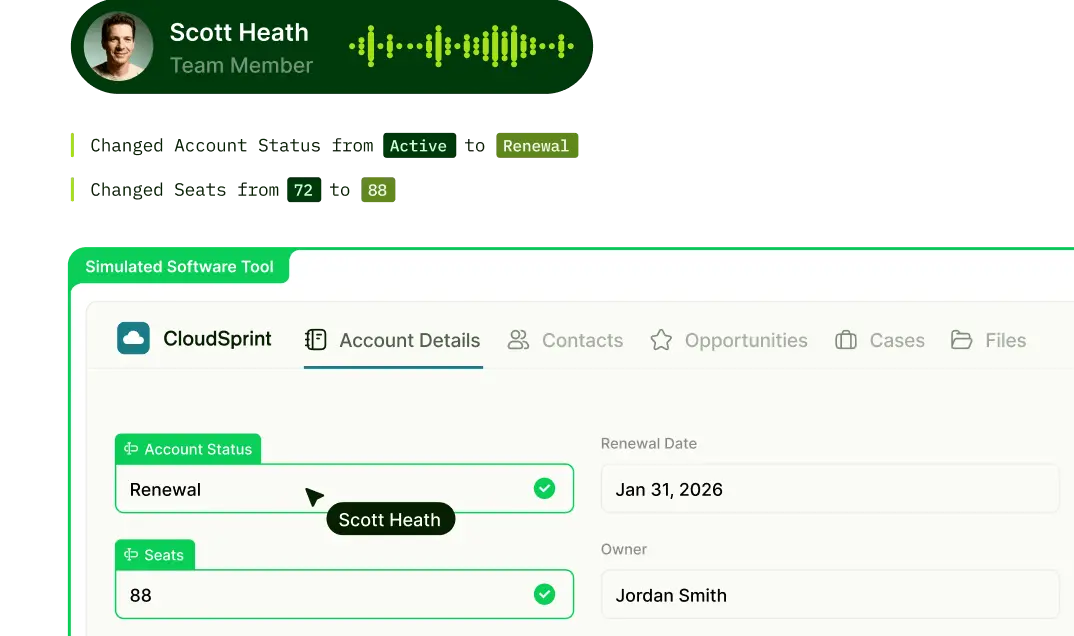
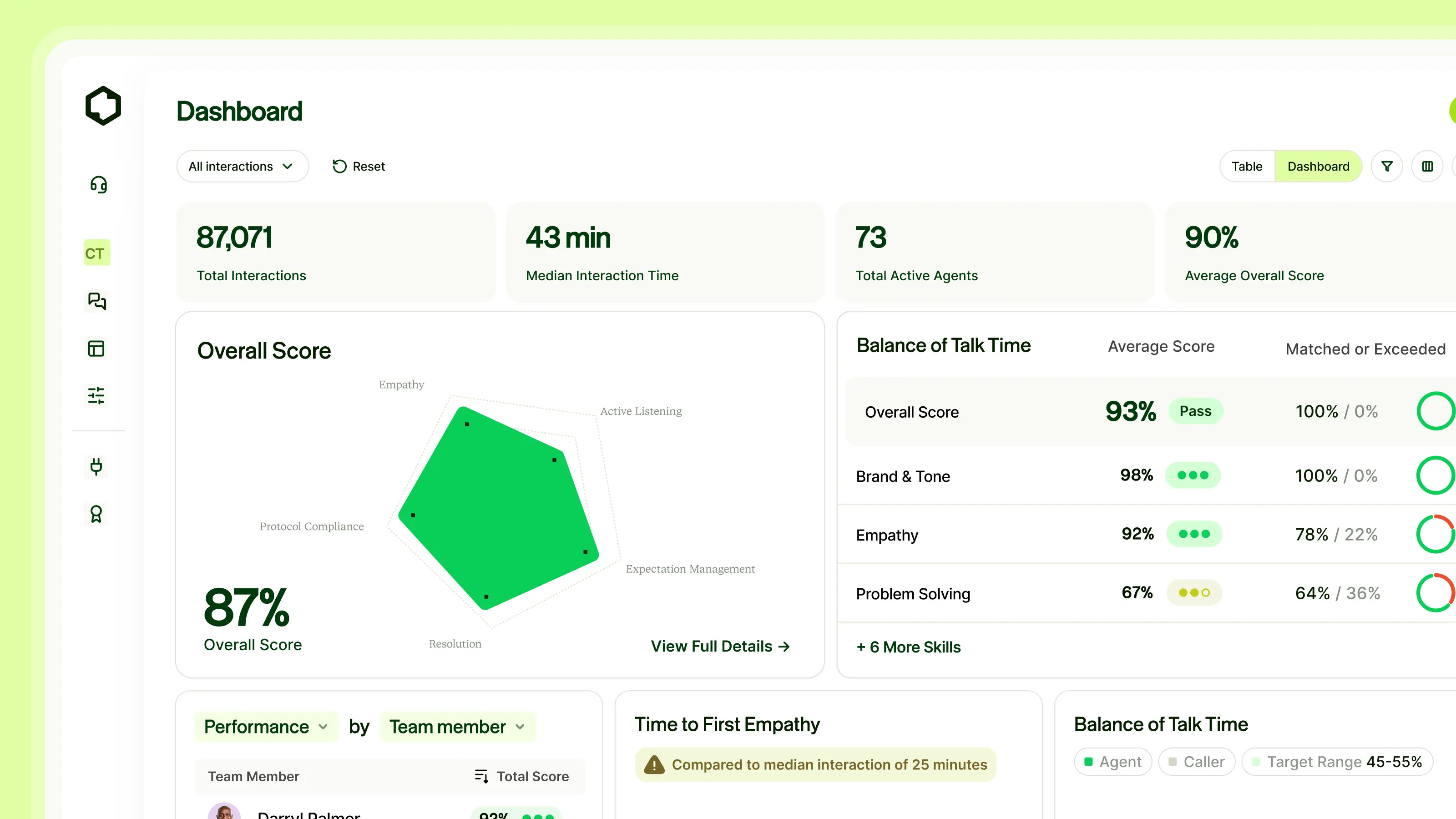
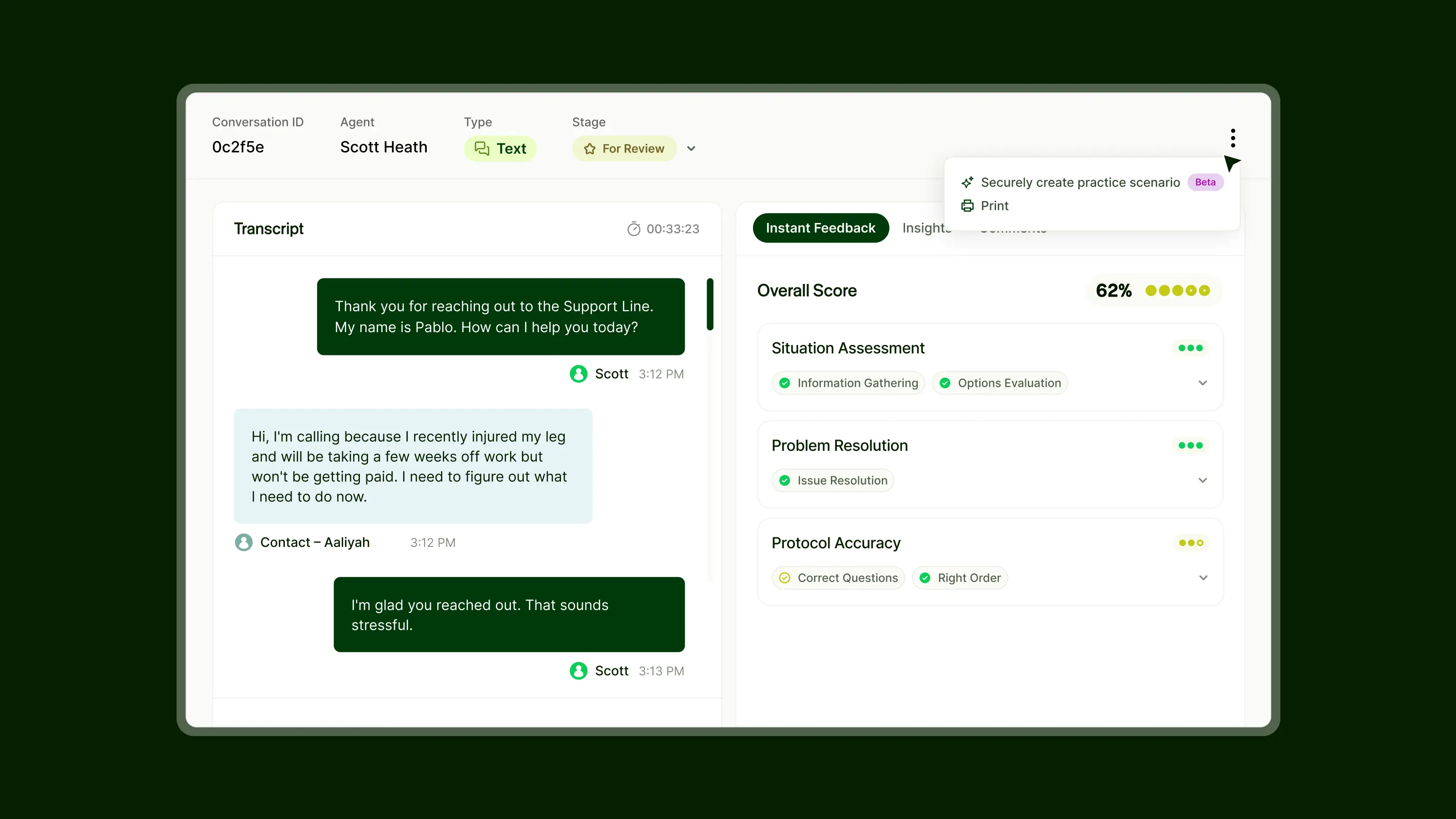
See What’s Happening at a Glance
Many QA teams audit fewer than 10% of calls, and the ones they do review are chosen semi-randomly. Performance signals are buried in spreadsheets that are already stale by the time anyone opens them. Leaders know problems exist but can’t see them in real time or at scale.
We’ve built a real-time operational layer that gives leaders visibility across all of their team’s live interactions: trends, outliers, and performance signals surfaced as they happen. Leaders can filter and drill down by agent, team, time period, topic, or scoring dimension, and save views to ensure organizational relevance. This is the command center that ties everything else together.
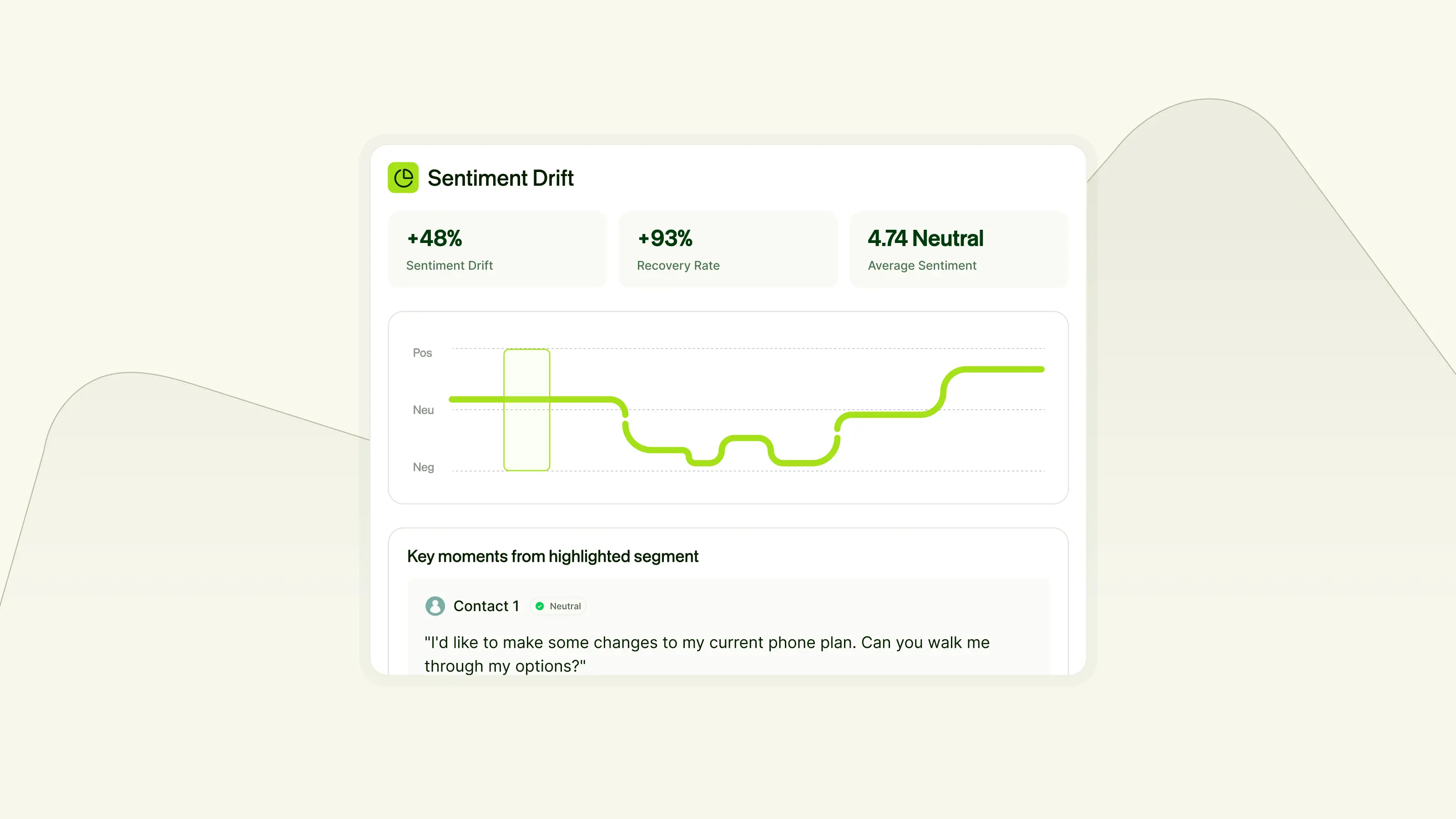
Understand the Emotional Arc
Most platforms give you an average sentiment score for a call and call it a day. But an average can mask a customer who went from calm to threatening to cancel — or one who called in furious and left genuinely grateful.
We show the full emotional trajectory: scored segments plotted on a visual timeline, with the specific quotes that drove each shift. Three metrics tell the story of what actually happened. Sentiment measures the shift from the point where the customer first articulates their problem to the end of the call — did the situation get better or worse? Recovery captures the rebound from the lowest point. And Average Sentiment provides the baseline. Together, they give QA leaders a more honest, actionable picture than any single number can.
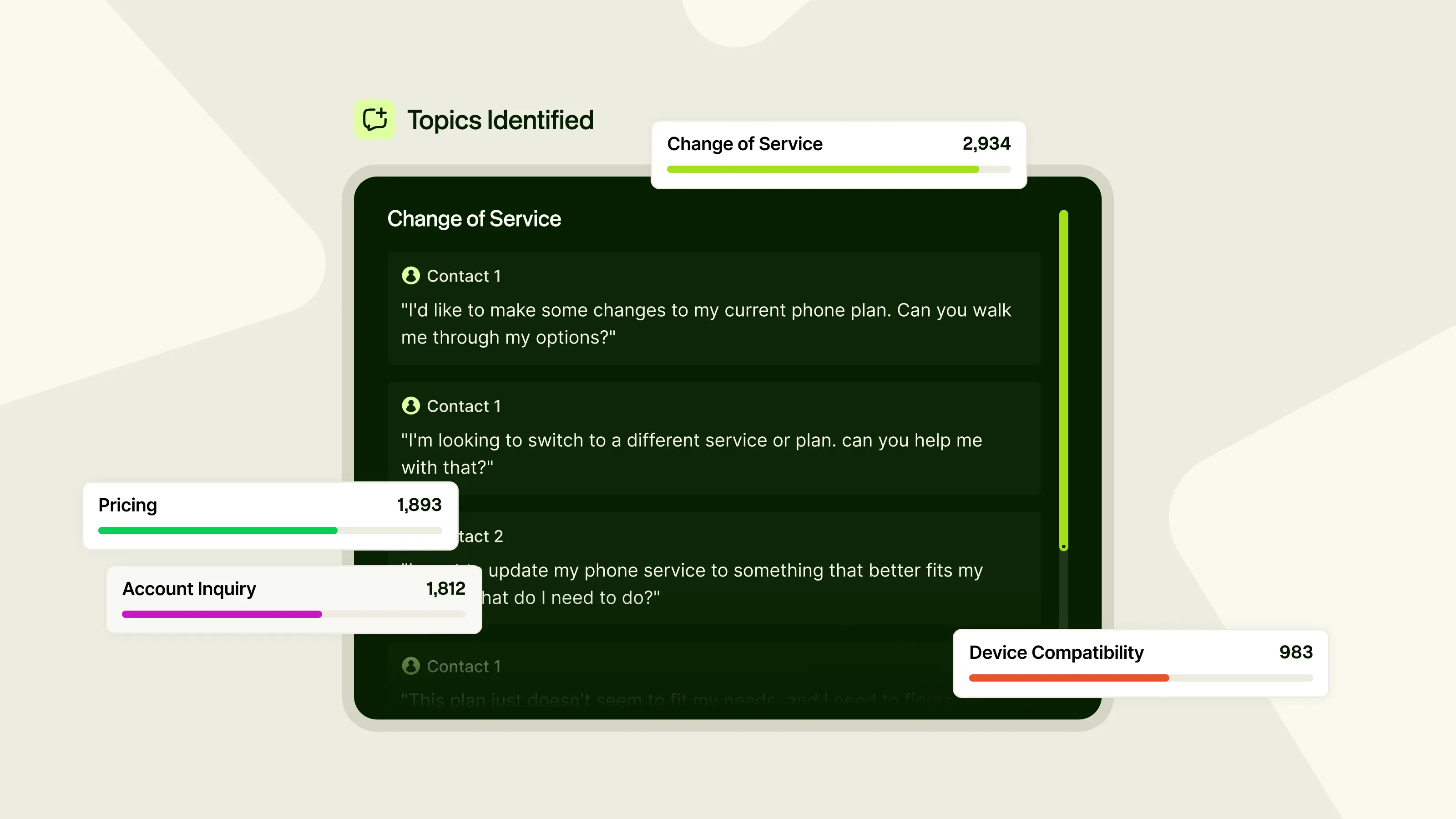
Know What Topics Are Driving Outcomes
When a QA leader sees a spike in negative calls, the first question is “about what?” Finding the answer today often requires manual searching or review. Leaders can’t quickly filter interactions by theme, spot emerging patterns, or separate agent-performance issues from product-friction issues.
Every conversation at ReflexAI can be automatically tagged with the subjects discussed, configured to each organization’s own terminology. Leaders can filter performance data by topic, spot emerging patterns, and understand which subjects consistently drive the hardest calls.
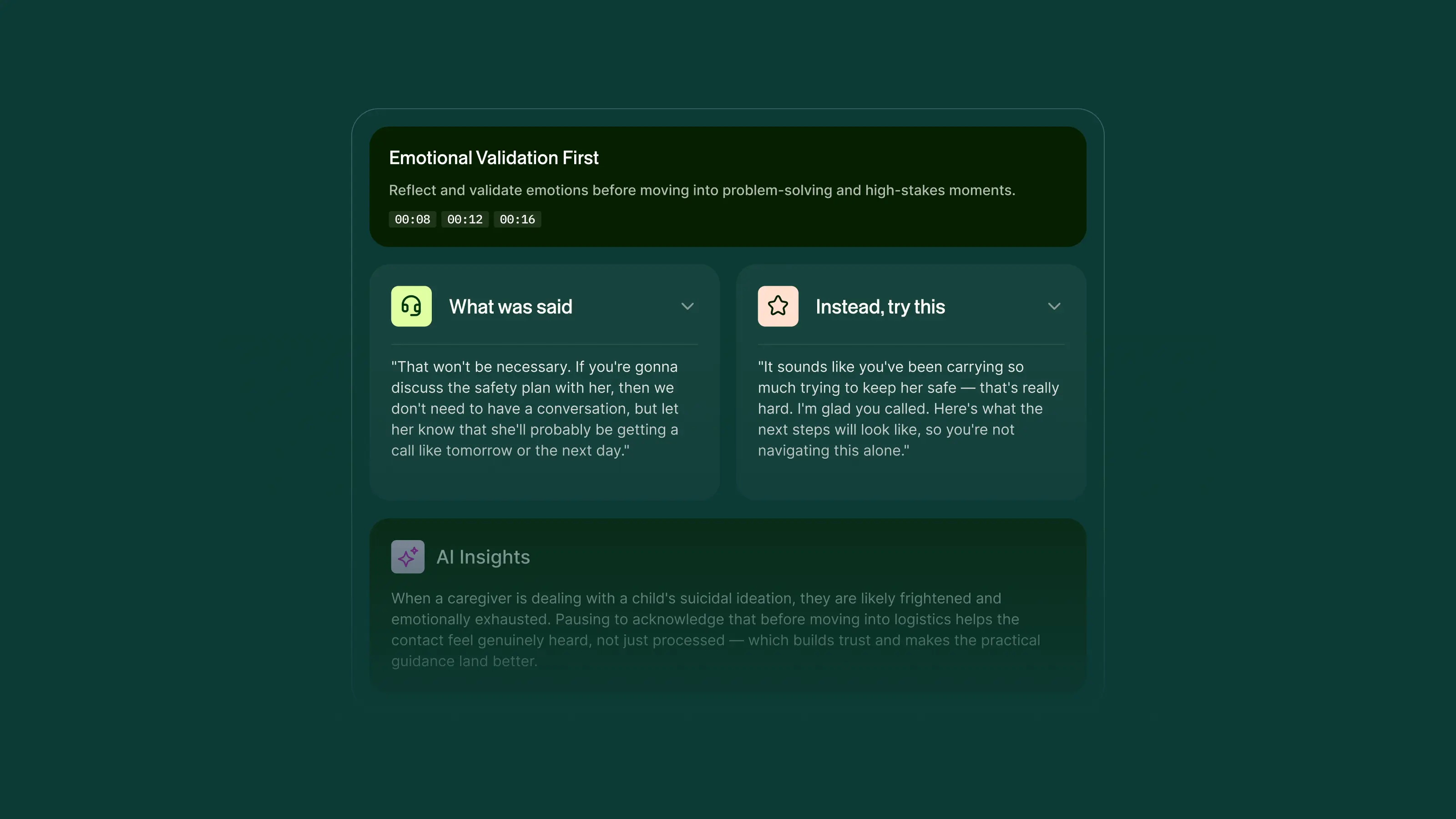
From Feedback to Coaching
Often when trainees finish a training experience, they get feedback at the dimension level: “improve your empathy.” But no one tells them what they actually said wrong or what they could say instead. Training managers compensate by manually annotating transcripts with rephrasing suggestions — often spending an hour per trainee. At cohort sizes of 100+, that’s unsustainable.
We’ve automated that entirely. After every scored simulation, the platform surfaces the exact transcript moments that impacted the score, organized under coaching themes. Each moment pairs what the trainee actually said with an AI-generated alternative calibrated to the evaluation criteria and scenario context, along with an explanation of why the change matters. Every training run now produces a concrete improvement plan — not a report card.
Assign Personalized Practice
The problem: The hardest part of the loop has always been acting on what you find. A QA manager spots a challenging call. A training leader knows which skills need work. But building a simulation that reflects the real scenario — the caller’s personality, the escalation path, the specific topic — has historically taken hours of manual design.
We’re collapsing that cycle. Leaders can generate a practice scenario directly from a real live interaction, with the context and complexity intact. A difficult call identified on Monday can become a targeted practice session by Tuesday — focused on the exact skill, the exact topic, and the exact type of conversation where the agent needs to improve. We’re starting with single-interaction generation and expanding to documentation-based and performance-data-based scenario creation from there.
The Loop, Connected
These aren’t isolated capabilities. They’re one system: see what’s happening across your operation in real time, understand the emotional arc and the topics driving outcomes, pinpoint the specific moments that matter in training, and turn all of it into targeted practice — continuously. When the practice runs are scored, those results feed right back into the dashboards, and the loop starts again.
If you’re ready to close the gap between insight and action, we’d love to show you how it works.